快速入门
JDP是企业级Core Data & Core AI 统一分析平台, JDP全称JDataFlow Platform
通过如下介绍,我们一步一步搭建基于JDP流分析平台的集群,能让你快速部署并且使用JDP进行业务应用开发。
如下是一个实例,介绍集群安装需要的硬件、网络、磁盘相关推荐信息。
JDP平台集群版本安装要求至少3个节点以上,其中涉及的zookeeper,kafka,clickhouse都是分布式集群系统,所以需要大于3个节点比较合理。
# 机架
操作系统版本CentOs7.2及以上,用户名root,密码123456。
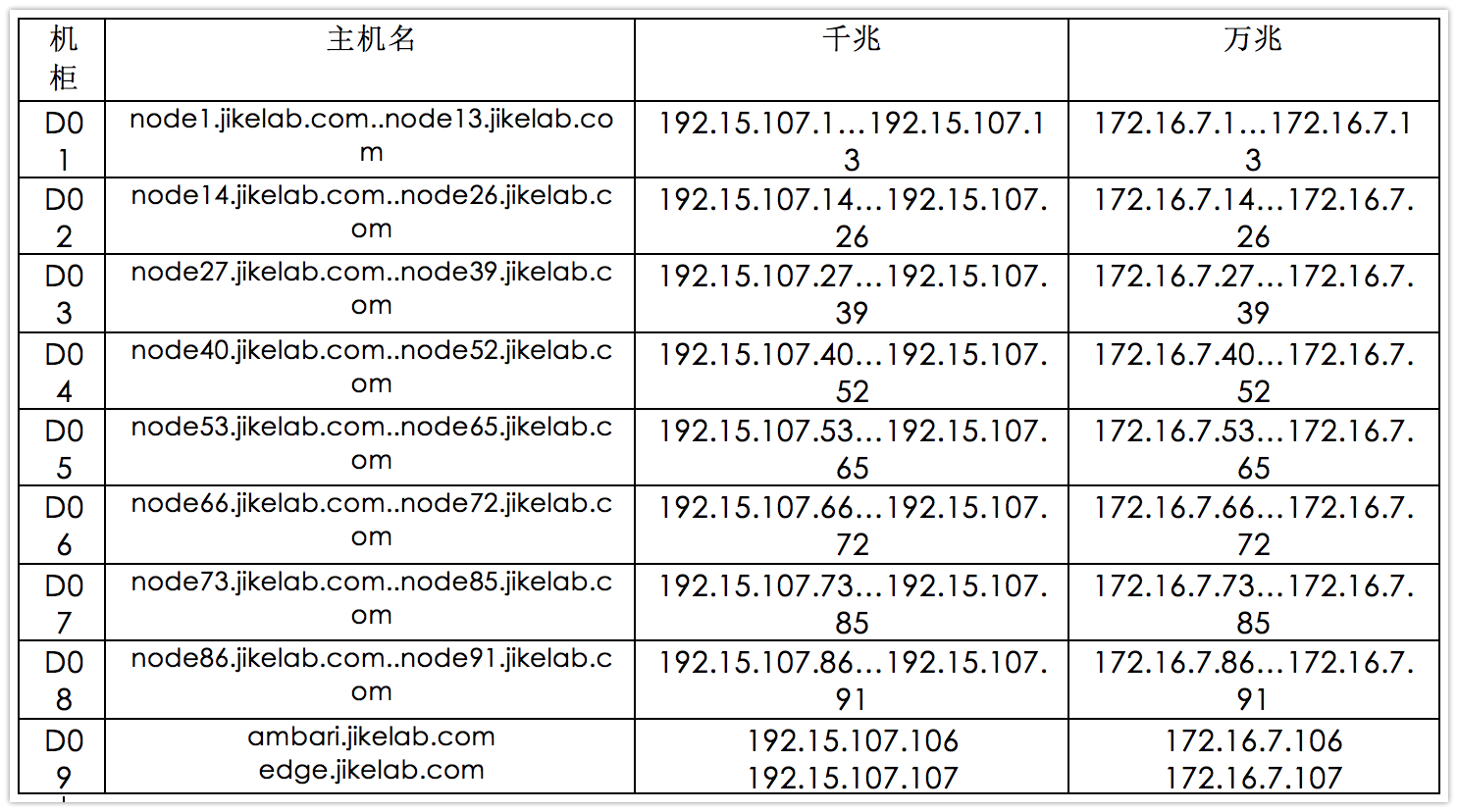
在集群安装前,需要收集集群的网络信息、规范主机名、所属机架,集群规划设计的时候需要使用。
# 网络
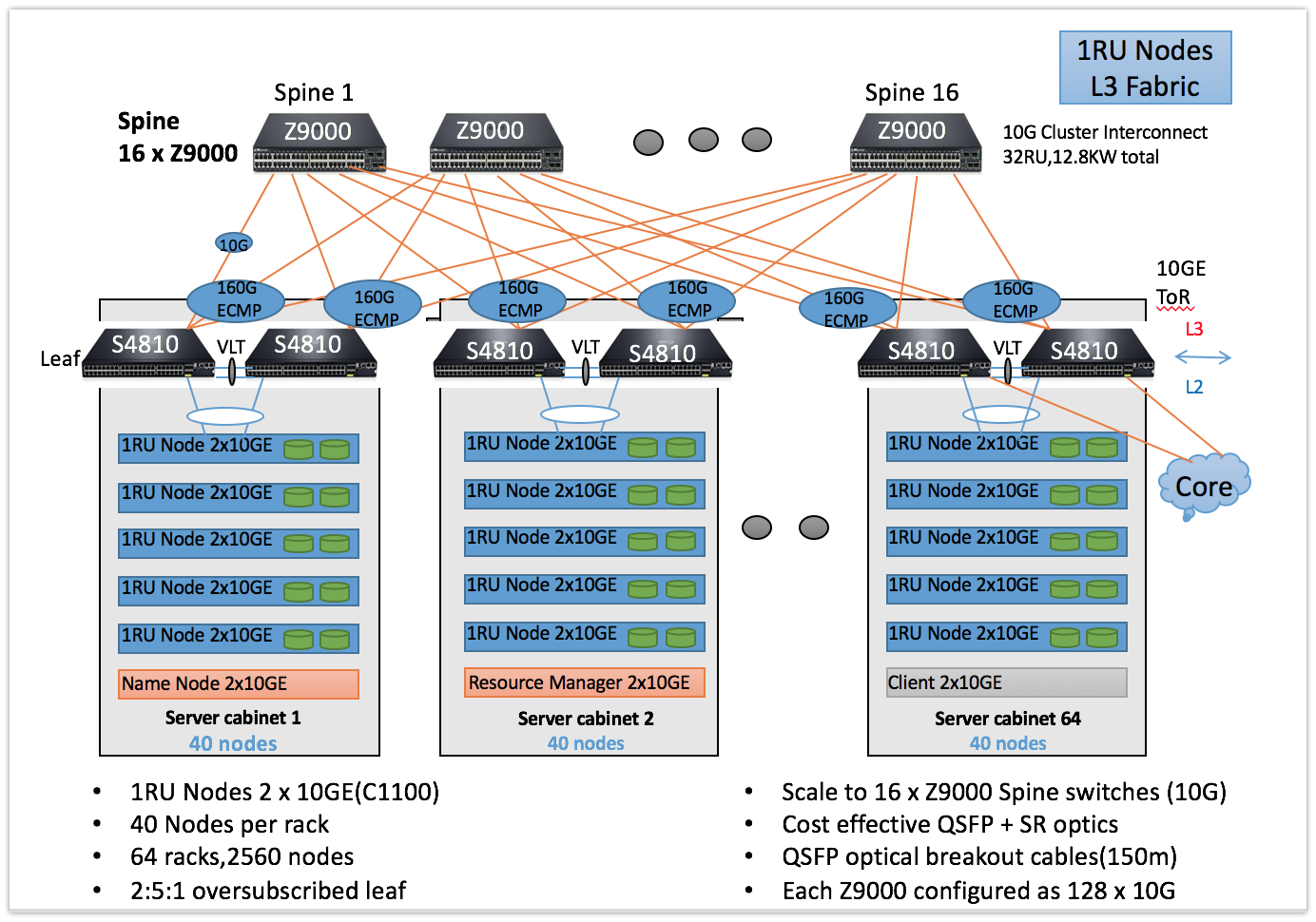
这篇内容,最核心也是最关键的内容,此图足矣表述。
如图,可容纳2560个节点的集群网络结构,构建10GE网络的庞大集群,网络设备是典型和核心层交换机、汇聚层交换机。图示为Dell的交换机产品,类似H3C、华为也有相关的硬件。需要Z9000 * 16台设备,Z9000是全40gb的汇聚交换。
物理层面划分64个rack,每个rack最大可容纳40台1RU服务器,总共可支撑2560个节点。具体部署过程中,注意主节点相关角色放到不同的机架上,Zookeeper节点放到不同机架。在后续内容有更加详细的介绍。
硬件配置和网络都需要有非常专业的工程师调试好,只有所有的环节优化到最佳,方才能在软件层面最大化把硬件资源利用起来,快速完成数据分析任务。
# 磁盘
-
ClickServer的配置:
- 2 * 600G SSD RAID1安装操作系统,10 * 2T or 4T SAS/SATA RAID10 Data Storage
-
Kafka Broker的配置
- 2 * 600G SSD RAID1安装操作系统、10 * 2T or 4T SAS/SATA Data Storage
-
设备盘符
- sda:SSD盘
- sdb-sdm:10 * SAS/SATA盘
-
CPU与内存
- ClickServer的配置:32核CPU,>=256G内存
- Kafka Broker的配置:24核CPU,>=128G内存
# 磁盘划分
下面图标,介绍不同的角色如何合理的划分磁盘。
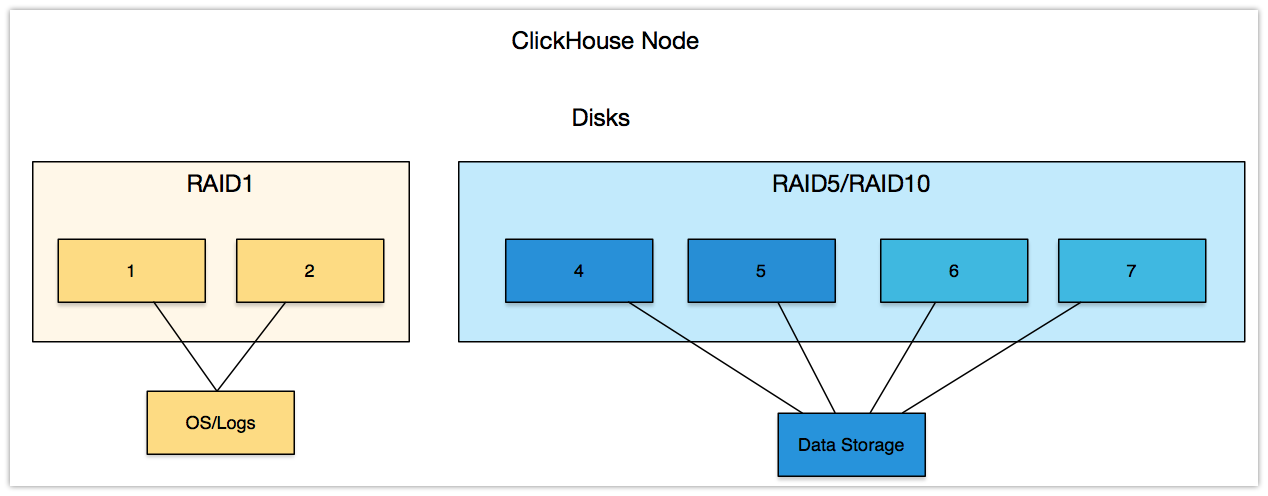
如图ClickServer Server节点, 为了保证数据可靠性可做RAID5/RAID10,也可在数据库启用副本策略支持容错。
有条件的情况 -> 生产环境中尽量保证,重要的角色管理的数据目录在物理上区分开,分而治之,方便管理。
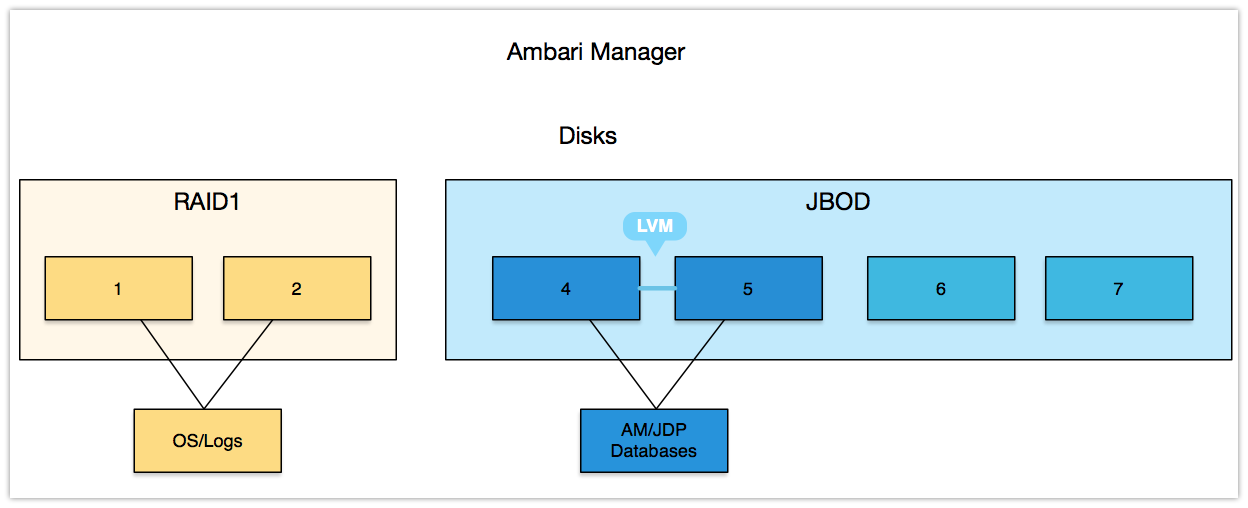
我们在部署Ambari Manager数据库中指定使用LVM,但RAID0也是一种选择。
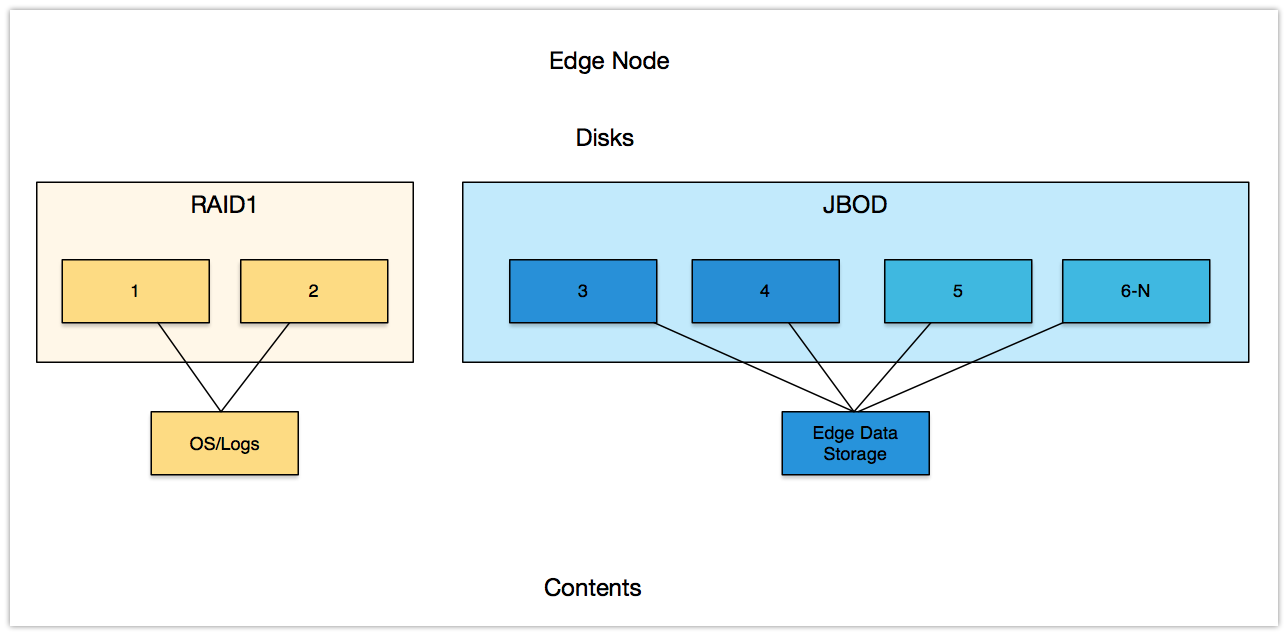
节点操作系统都是2块盘做RAID1,根据不同的角色磁盘划分有区别,在ClickHouse Server节点可做RAID保障数据可靠性;Kafka Borker节点,直接使用裸盘挂载存储数据。
其他,相关服务,直接安装于Edge节点,在物理目录区分相关数据存储。
集群的安装方式选择Ambari来进行自动化安装,目前Ambari是开源的大数据管理工具。Ambari是支持多平台的一款大数据自动化部署和管理软件,我们JDP平台就是通过Ambari来实现自动化管理。
# 系统分区
Linux系统分区,在做Linux系统分区的时候, 决定了后续集群是否能够在底层提供合理的数据存储保障能力。比如:操作系统”os/log”需要安装在SSD,那么SSD需要2块做raid1,保障即使有一块盘损坏,保障集群操作系统正常运行。
注意:系统安装的时候,请使用最小化安装方式,不安装图形化界面.
- ClickHouse Server节点分区方式:
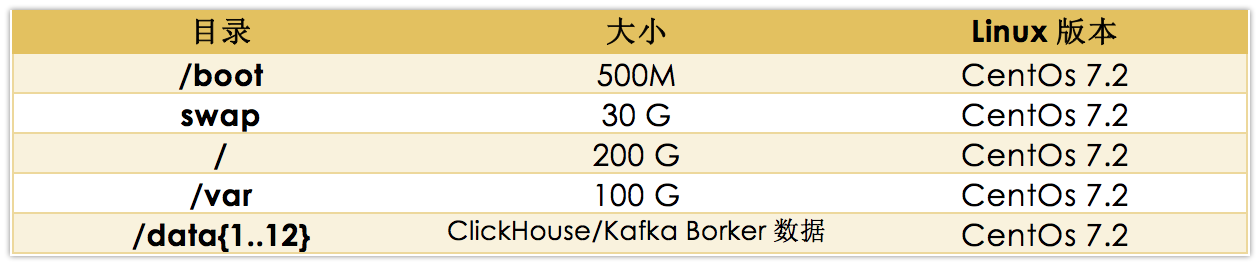
这是一个例子,可根据实际情况调整,需要注意的第一点是/var目录单独分出来,避免日志太多导致根目录爆满,导致操作系统无法正常工作。第二点,ClickHouse Server数据存储目录,底层硬盘为RAID5/RAID10,裸盘也没问题,但是得保障在ClickHouse集群层面有多数据副本。第三点,ClickHouse Server存储一般需要非常大的空间,因为所有的集群数据都存储在ClickHouse Server管理的磁盘上, 建议单块盘大小2-4T。
由于ClickHouse Server目前还未支持多目录存储数据,只能固定在一个存储路径。所以官方建议可以通过软连接解决往多块盘同时写的问题,在未来版本中会支持多存路径。
- Ambari-Server节点分区方式:
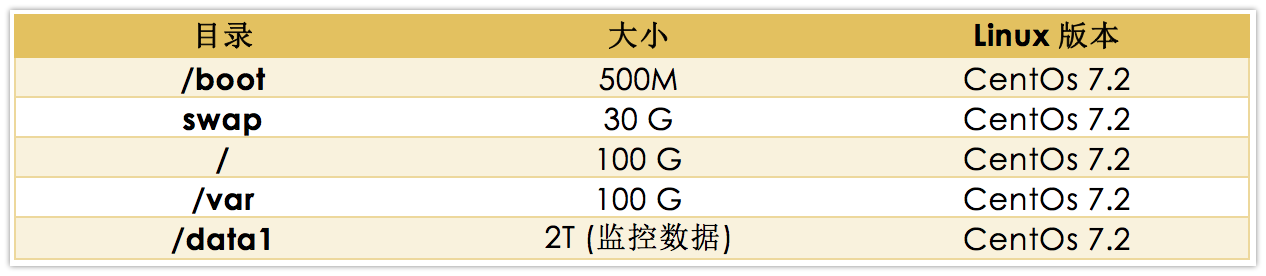
这是一个例子,对于集群监控主节点的部署,使用Ambari-Server监控集群或者其他集群监控工具,原则是操作系统建议使用lvm分区管理,方便动态扩展容量,避免出现某些目录占满的情况。监控相关的数据一定要放到大盘去存储,设置好数据清理周期,避免存储数据过大,导致查询时主节点压力过大。
- Gaeteway-Node节点分区方式:
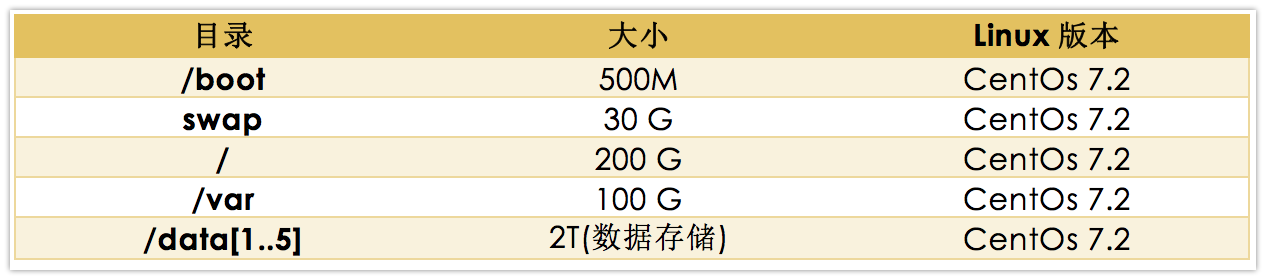
Gateway节点,没有任何集群服务和组件,通常是用来和集群沟通提交任务的节点,主要功能,在JDP集群中提供一个桥梁,可以对数据进行接入 。Gateway节点链接到主要局域网的入口, 有时也被称作网关节点。Gateway节点是可选或者不选择的,但常被强烈推荐,对集群瓶颈和性能均有很大的提升作用。
Linux系统分区方案说明:
在很多业务服务器数量多且复杂的运维场景,会有专门的系统安装工程师,由于这些基础系统安装工程师无法确定服务器的业务需求,因此,会根据公司的要求只分出:
- /boot 200M
- Swap 内存*2
- / (列如: 200G)
然后剩余的分区保留不分,fdisk(不适合大于2t的分区),parted(适合大于2T的分区) 这样后续使用的服务器的不同业务产品的运维部门就可以根据具体的业务在规划后面的分区,这样的方法也是值得推荐的分区思路!
上面的/data{1..12}目录,表示,如果有12块硬盘,挂载点为12个目录,取名/data1, /data2, /data3, /data..这些目录都用来存储ClickHouse/Kafka Broker数据的数据目录!
有关根目录/ ,主要是存储/home,/tmp,/opt等!
有关/var目录主要存储相关组件所有的日志记录信息,所以单独划分,避免根目录出现使用100%的情况,导致操作系统无法正常工作。
# 角色分配
由于您选择使用Ambari Manager进行集群的自动化部署方式,下面图表显示了在大多数集群的安装时合理化的角色划分方式。
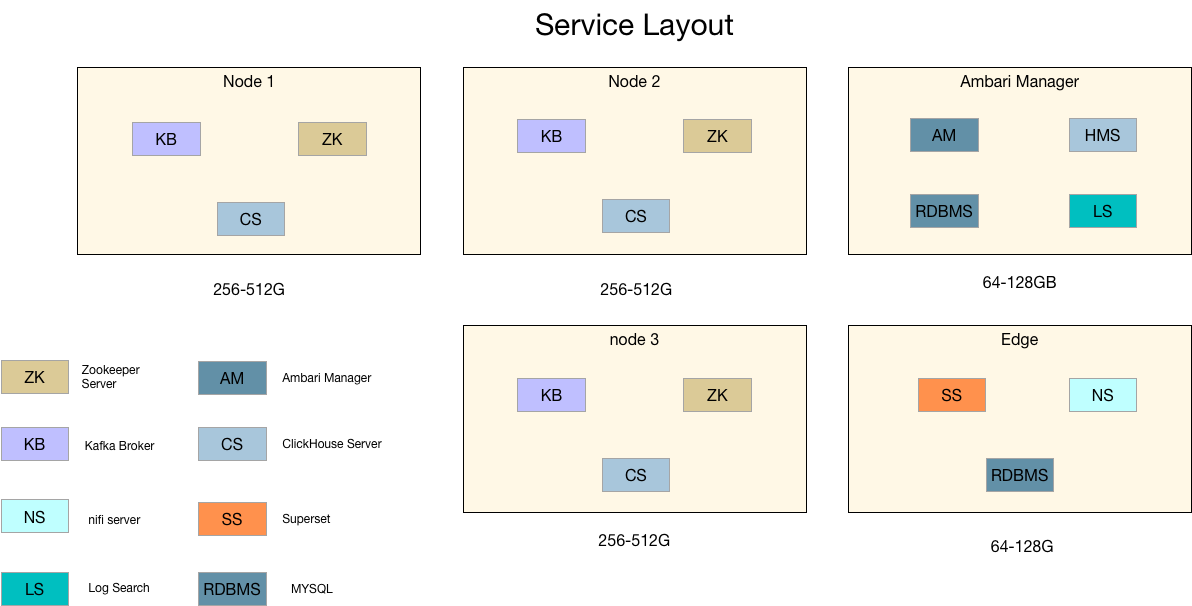
我们建议每个ClickHouse Server节点内存256-512G。内存相对便宜,并且随着对计算引擎越来越高的要求,引入内存计算充分利用内存,快速响应。
角色分配原则,有单点的问题的服务集中在一台机器,方便管理,可视化相关对外提供服务部署在Edge节点。如果监控节点(Ambari Server)没有HA功能,可以通过定时对监控服务节点进行备份数据和数据库快照,即使在监控服务器损坏的情况下,依然可以通过数据库备份数据在一个全新的服务器上恢复监控服务,而不会影响任何管理组件的正常运行。
目前Ambari Server是可以支持迁移到新的服务器节点恢复,可以参考我的历史文章。
需要注意,在大集群(50+ 节点)中,一定要提前统计好服务器所属机架,方便管理和服务分配。
- Server Node:ClickHouse Server、Kafka Borker、ZKServer、NIFI Server
- Ambari Manager:Ambari Server、ZKServer
ZKServer保证奇数个节点,这里涉及到3个管理节点,物理上对应着3台物理服务器,在物理逻辑上保证他们尽量放置于不同的机架。
接下来,我们将介绍如何安装JDP平台。
# 必备条件
[1] 选择操作系统版本
关于支持的操作系统
目前仅支持R系列操作系统7.x版本,比如:centos/redhat 7.2,7.3,7.4。
注意:
请不要尝试在其他系统安装,目前我们还未提供支持,安装失败属于正常现象。
注意:内容基于7.4.1708 (Core)版本安装并编写而成。
[2] Ambari-server所在的服务器能够ssh免密码登录到全部主机。
[3] 全部主机关闭selinux
setenforce 0 && sed –i 's#SELINUX=enforcing#SELINUX=disabled#g' /etc/selinux/config
[4] 所有节点主机名统一格式
例如:
- ClickHouse Server: node{001..100}.fulsionlab.cn
[5] 全部主机名和IP地址进行映射hosts
[6] 全部机器关闭防火墙
systemctl stop firewalld.service && systemctl disable firewalld.service
[7] 全部主机必须通过ntp服务使时间保持一致。
公网NTP同步;如果是内网,需要自己做一个内网的NTP服务器;让服务器时间和硬件时钟同步,避免重启操作系统导致时间不同步,集群组件无法正常工作。
ntpdate asia.pool.ntp.org && hwclock -w
集群组件利用时间戳进行存储的,需要保障集群所有节点时间一致性,不然会导致集群异常,目前在分布式数据库领域,对于分布式集群时间一致性的误差不能超过秒级,在JDP中Zookeeper组件,如果在集群安装之前你没有主动的去让所有节点时间一致,安装完成之后再去同步时间,会导致依赖Zookeeper服务的ClickHouse不能正常工作。
目前NewSQL数据库系统也是严格要求必须保证同一数据中心时间一致,甚至通过硬件时钟来做时间同步。
[8] 安装epel-release(可选)
yum install epel-release -y
因为JDP流分析平台中的Superset组件,支持异步数据查询,依赖到epel源中的lapack、openblas-devel优化的BLAS库。
# 制作本地源
JDP流分析平台,支持在线安装和离线安装两种模式。但是由于个人开发者,能力有限,目前线上服务器提供可部署的JDP二进制文件流量已经比较可观,为了不对我的VPS服务器造成太大压力。故而建议大家使用离线安装包部署的方式,由于涉及到多个分布式系统融合,所以软件包比较大。
全靠个人收入支撑服务器,所以希望多多包涵。
接下来,我接受一下JDP离线安装的方法。
你可以选择集群任意节点安装httpd服务,如下考虑在你没有内网源服务器的情况下进行的操作。
[1] 安装httpd服务
yum install httpd
[2] 启动httpd服务
如果你按照之前的必备条件准备,并且选择集群任意节点做为httpd服务器,那么直接启动即可。
如果你选择的一台全新服务器安装httpd,没有使用集群节点,那么你需要关闭selinux和firewalld。
systemctl start httpd
systemctl enable httpd
[3] 下载JDP-3.2.0.0安装包
wget http://fuslab.github.io/jdp/repo-as-tarball/3.2.0.0/JDP-3.2.0.0-centos7-rpm.tar.gz
软件包比较大,大约需要下载5min
3% [=> ] 93,634,920 7.11MB/s eta 5m 33s
由于JDP下载量太大,导致国外的IP BLACKED,目前已无法稳定使用。
所以,提供百度云盘,下载地址:
链接:https://pan.baidu.com/s/1Xgh-PbPURgSYG2XUJOU6HA
密码:frsj
[4] 解压JDP-3.2.0.0到/var/www/html路径
mkdir /var/www/html/jdp/
tar -zxvf JDP-3.2.0.0-centos7-rpm.tar.gz -C /var/www/html/jdp/
[5] 验证JDP源可用性
[f1@host html]$ pwd
/data/nginx/html
[f1@host html]$ tree -L 2 jdp/centos7/
jdp/centos7/
├── 3.x
│ ├── 3.2.0.0
│ ├── ambari
│ ├── ambari.repo
│ └── jdp-3.2.repo
└── utils
└── 1.1.0
通过http://you_httpd_ip/jdp/centos7/3.x/访问,如图,说明源路径没问题。
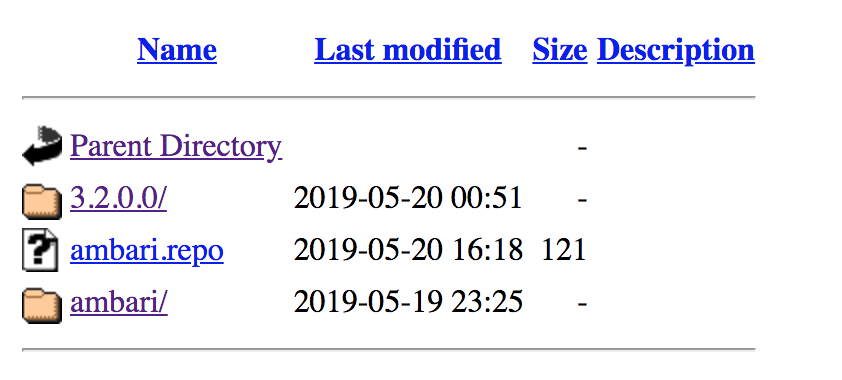
通过yum search验证源是否可用。
wget http://you_httpd_ip/jdp/centos7/3.x/ambari.repo -O /etc/yum.repos.d/ambari.repo
修改ambari.repo中的baseurl=http://you_httpd_ip/jdp/centos7/3.x/ambari/
然后执行如下命令:
yum search ambari
如果有相关ambari软件信息,那么恭喜你,JDP离线源成功了。
# Ambari安装
[1] ambari-server节点生成相关的repo文件,命令如下:
curl http://you_httpd_ip/jdp/centos7/3.x/ambari.repo > /etc/yum.repos.d/ambari.repo
修改ambari.repo中的baseurl=http://you_httpd_ip/jdp/centos7/3.x/ambari/
[2] 安装ambari-server
yum install ambari-server -y
[3] 配置Ambari-Server的JDK,JDP平台所需JDK必须 >= 1.8
wget http://fuslab.github.io/jdp/artifacts/jdk-8u112-linux-x64.tar.gz -O /var/lib/ambari-server/resources/jdk-8u112-linux-x64.tar.gz
wget http://fuslab.github.io/jdp/artifacts/jce_policy-8.zip /var/lib/ambari-server/resources/jce_policy-8.zip
由于JDP下载量太大,导致国外的IP BLACKED,目前已无法稳定使用。
所以,提供百度云盘,下载地址,注意此处JDK需要验证策略文件,百度云Download请参考如上操作:
链接: https://pan.baidu.com/s/1Xgh-PbPURgSYG2XUJOU6HA
密码: frsj
[4] ambari-server setup
[root@node1 ~]# ambari-server setup
Using python /usr/bin/python
Setup ambari-server
Checking SELinux...
SELinux status is 'enabled'
SELinux mode is 'permissive'
WARNING: SELinux is set to 'permissive' mode and temporarily disabled.
OK to continue [y/n] (y)?
Customize user account for ambari-server daemon [y/n] (n)?
Adjusting ambari-server permissions and ownership...
Checking firewall status...
Checking JDK...
[1] Oracle JDK 1.8 + Java Cryptography Extension (JCE) Policy Files 8
[2] Custom JDK
==============================================================================
Enter choice (1): 1
To download the Oracle JDK and the Java Cryptography Extension (JCE) Policy Files you must accept the license terms found at http://www.oracle.com/technetwork/java/javase/terms/license/index.html and not accepting will cancel the Ambari Server setup and you must install the JDK and JCE files manually.
Do you accept the Oracle Binary Code License Agreement [y/n] (y)? y
Downloading JDK from http://fuslab.github.io/jdp/artifacts/jdk-8u112-linux-x64.tar.gz to /var/lib/ambari-server/resources/jdk-8u112-linux-x64.tar.gz
jdk-8u112-linux-x64.tar.gz... 100% (174.7 MB of 174.7 MB)
Successfully downloaded JDK distribution to /var/lib/ambari-server/resources/jdk-8u112-linux-x64.tar.gz
Installing JDK to /usr/jdk64/
Successfully installed JDK to /usr/jdk64/
Downloading JCE Policy archive from http://fuslab.github.io/jdp/artifacts/jce_policy-8.zip to /var/lib/ambari-server/resources/jce_policy-8.zip
Successfully downloaded JCE Policy archive to /var/lib/ambari-server/resources/jce_policy-8.zip
Installing JCE policy...
Check JDK version for Ambari Server...
JDK version found: 8
Minimum JDK version is 8 for Ambari. Skipping to setup different JDK for Ambari Server.
Checking GPL software agreement...
GPL License for LZO: https://www.gnu.org/licenses/old-licenses/gpl-2.0.en.html
Enable Ambari Server to download and install GPL Licensed LZO packages [y/n] (n)?
Completing setup...
Configuring database...
Enter advanced database configuration [y/n] (n)?
Configuring database...
Default properties detected. Using built-in database.
Configuring ambari database...
Checking PostgreSQL...
Running initdb: This may take up to a minute.
Initializing database ... OK
About to start PostgreSQL
Configuring local database...
Configuring PostgreSQL...
Restarting PostgreSQL
Creating schema and user...
done.
Creating tables...
done.
Extracting system views...
ambari-admin-2.7.0.0.0.jar
Error extracting ambari-views-package-2.5.0.0.0.jar
....
Ambari repo file doesn't contain latest json url, skipping repoinfos modification
Adjusting ambari-server permissions and ownership...
Ambari Server 'setup' completed successfully.
[5] 启动 ambari-server
[root@node1 ~]# ambari-server start
Using python /usr/bin/python
Starting ambari-server
Ambari Server running with administrator privileges.
Organizing resource files at /var/lib/ambari-server/resources...
Ambari database consistency check started...
Server PID at: /var/run/ambari-server/ambari-server.pid
Server out at: /var/log/ambari-server/ambari-server.out
Server log at: /var/log/ambari-server/ambari-server.log
Waiting for server start.........................................................
Server started listening on 8080
DB configs consistency check: no errors and warnings were found.
Ambari Server 'start' completed successfully.
ambari-server 启动成功,开始安装JDP集群。
# JDP集群安装
浏览器输入http://your_ambari-server_ip:8080/#/login 用户名:admin 密 码:admin
通过登录页面进入集群安装向导,如下所示。
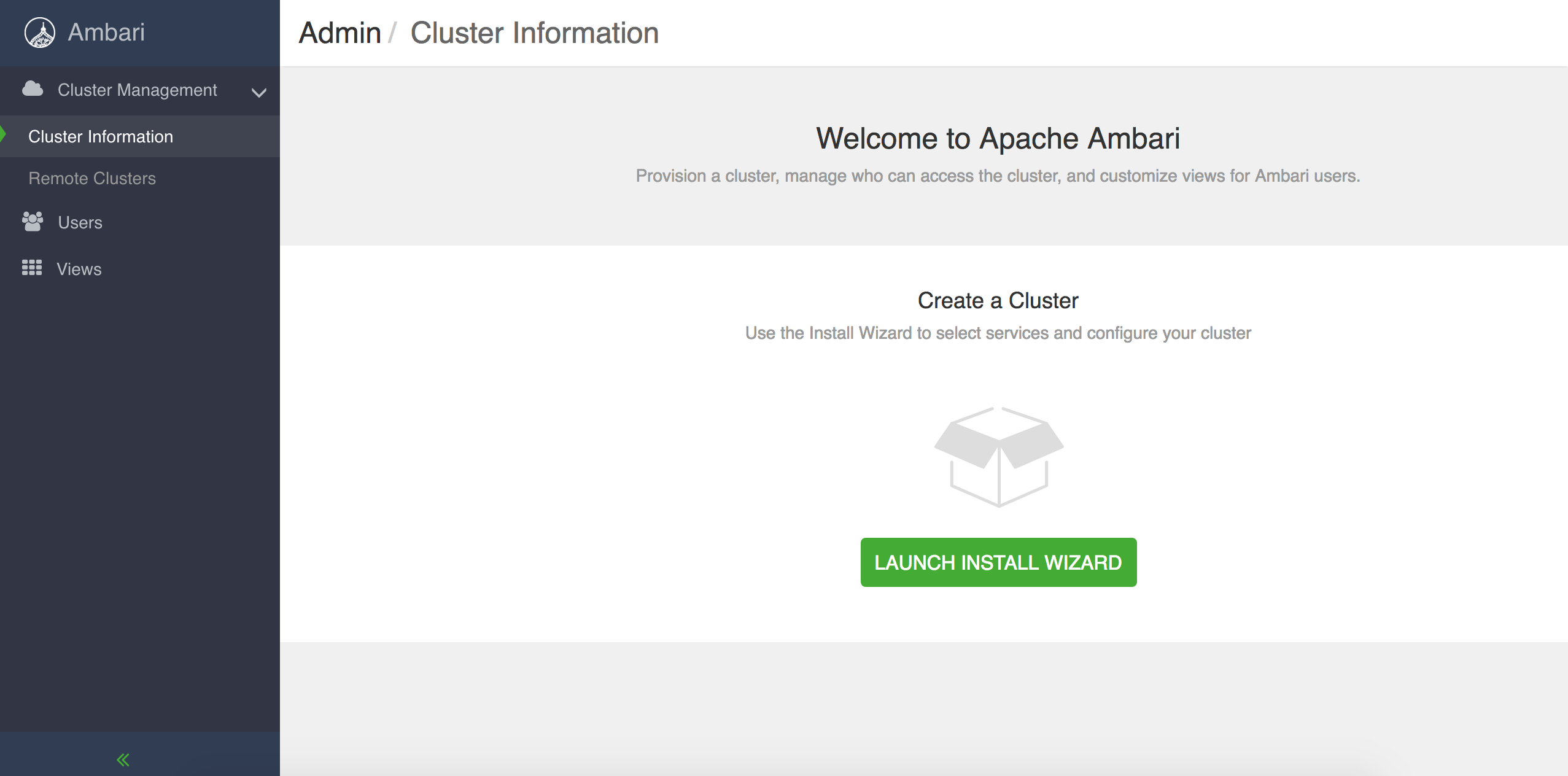
通过鼠标单击”Launch Install Wizard”按钮,通过10个setup引导步骤,进行可视化的集群安装。
# Step1 - Get Started
步骤1,需要填入一个集群名称Cluster Name,点击下一步。例如:

# Step2 - Select Version
选择使用JDP的版本,默认支持3.2版本的安装部署,鼠标点击“Use Local Repository”填入之前制作的本地仓库源地址,点击下一步:
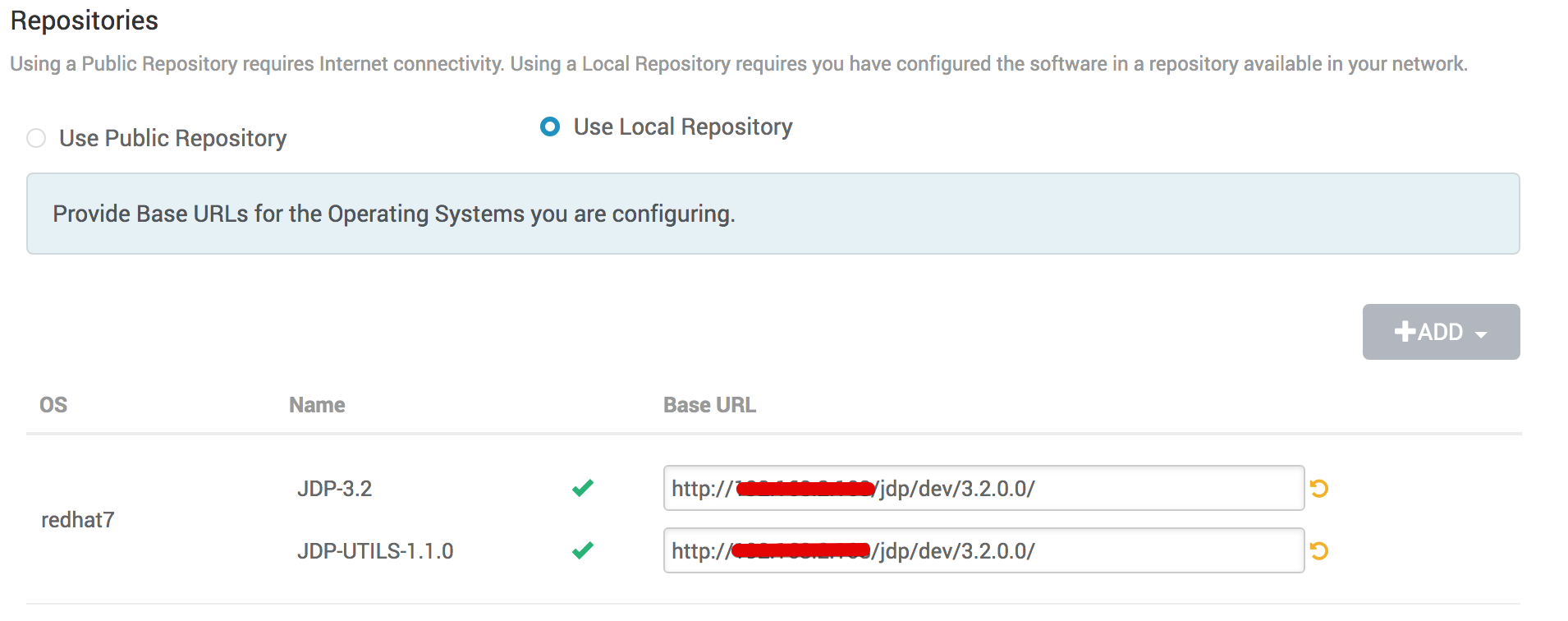
如上图,默认支持redhat7:
- JDP-3.2 Base URL:
http://you_httpd_ip/jdp/centos7/3.x/3.2.0.0 - JDP-3.2 JDP-UTILS-1.1.0 Base URL:
http://you_httpd_ip/jdp/centos7/3.x/3.2.0.0
# Step3 - Install Options
填写需要安装的目标主机节点的hosts映射名称,私钥信息填写为ambari-server所在节点,可以免密码登录所有节点的用户私钥信息。例如:一般通过root用户进行集群的安装,如下填写root用户/root/.ssh/id_rsa文件内容。
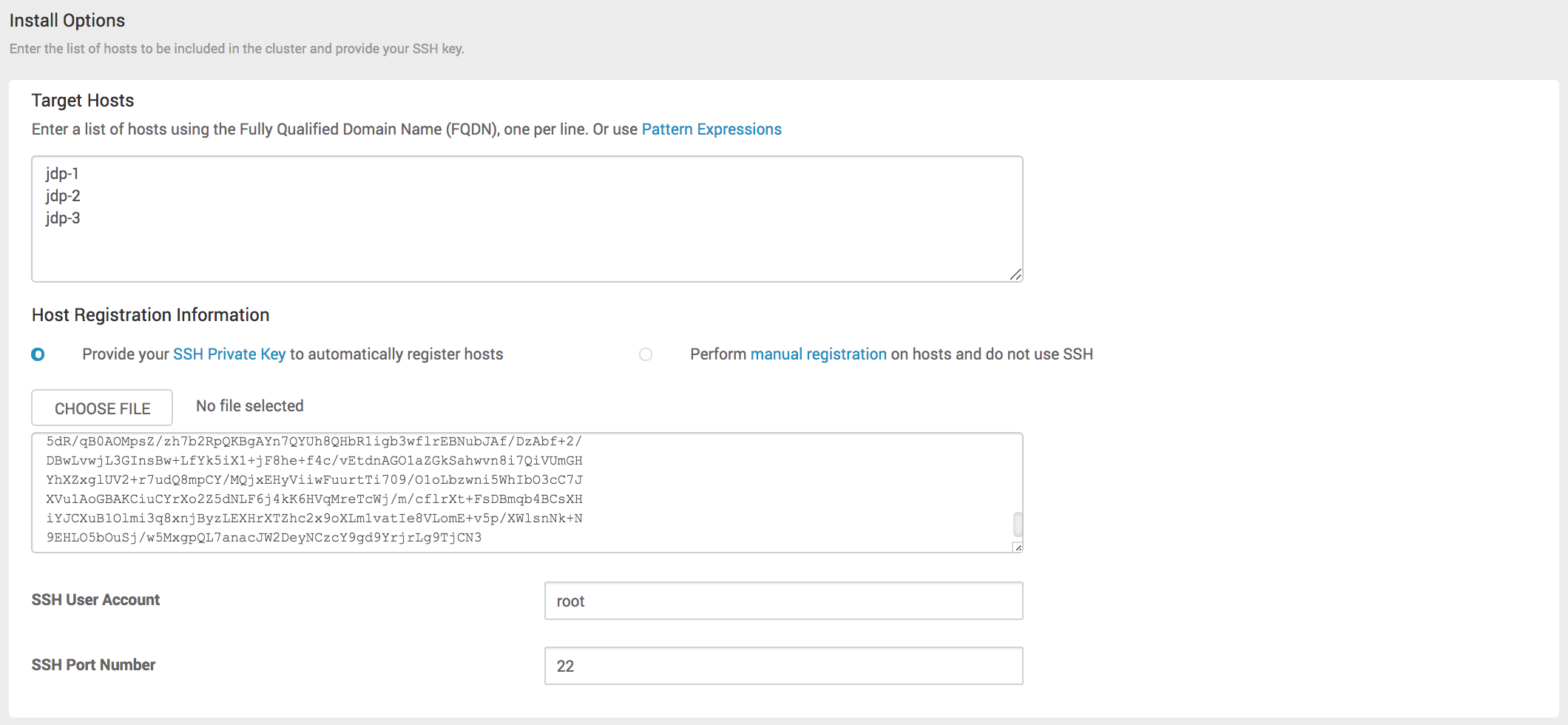
点击“Register and Confirm”进入下一步。
# Step3 - Confirm Hosts
在这个步骤ambari-server节点会并行去多台机器执行相关命令。首先scp相关的ambari-agent的setup脚本到多台机器,然后并行执行相关的命令进行ambari-agent的安装,注册ambari-agent节点到ambari-server。这里主要工作是在所有节点安装ambari-agent,并且把ambari-agent注册到ambari-server,让server可以控制所有的agent节点。之后ambari-server就可以控制所有的agent执行命令进行JDP集群的安装;自动注册用到了ssh免密码登录,这就是为什么需要ambari-server所在节点需要可自动化登录到所有受管理节点的权限。
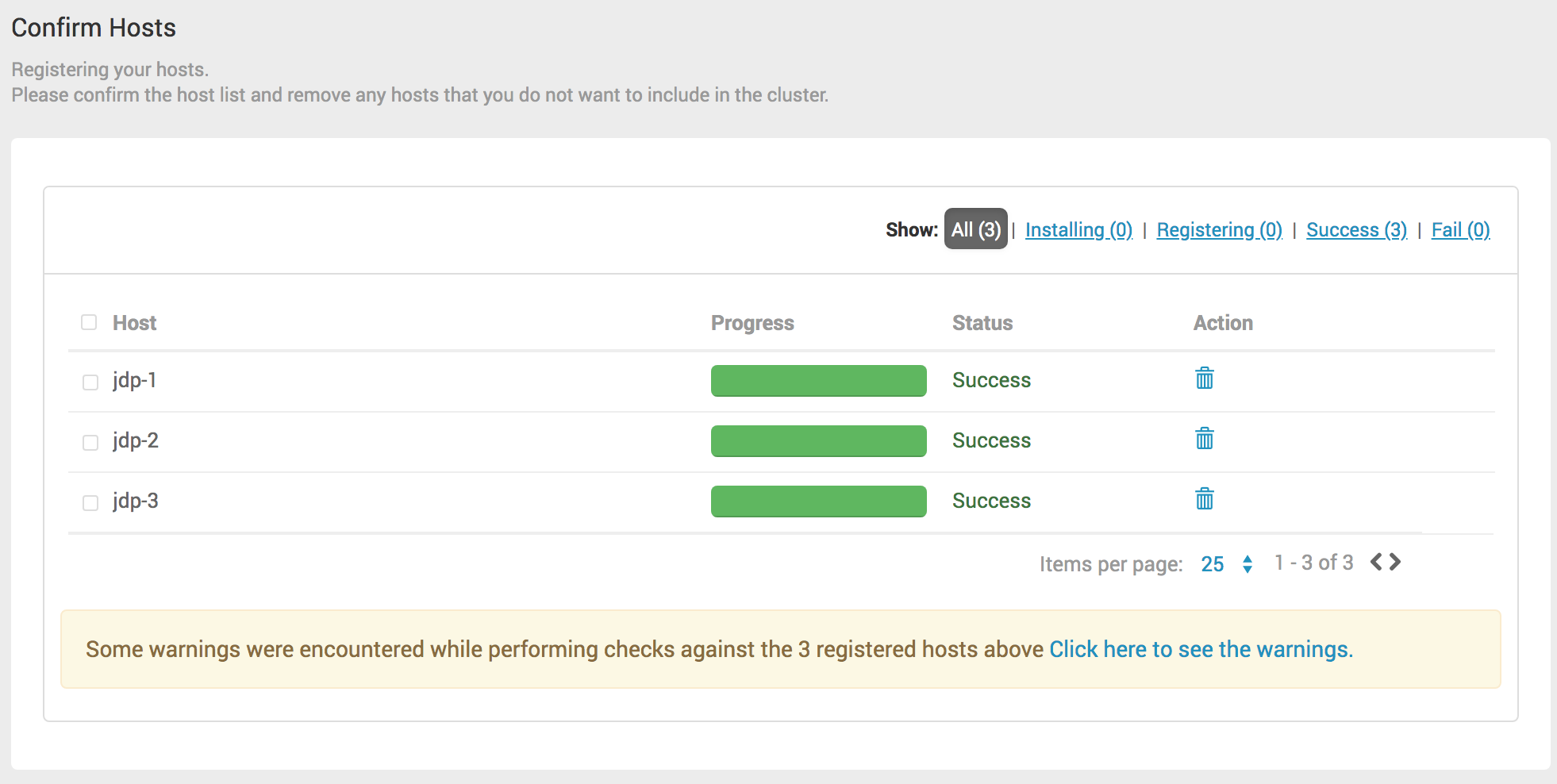
点击“Next”继续安装。
# Step4 - Choose Services
选择你需要安装的服务,目前JDP提供12个组件的自动化安装和部署维护。如下图所示:
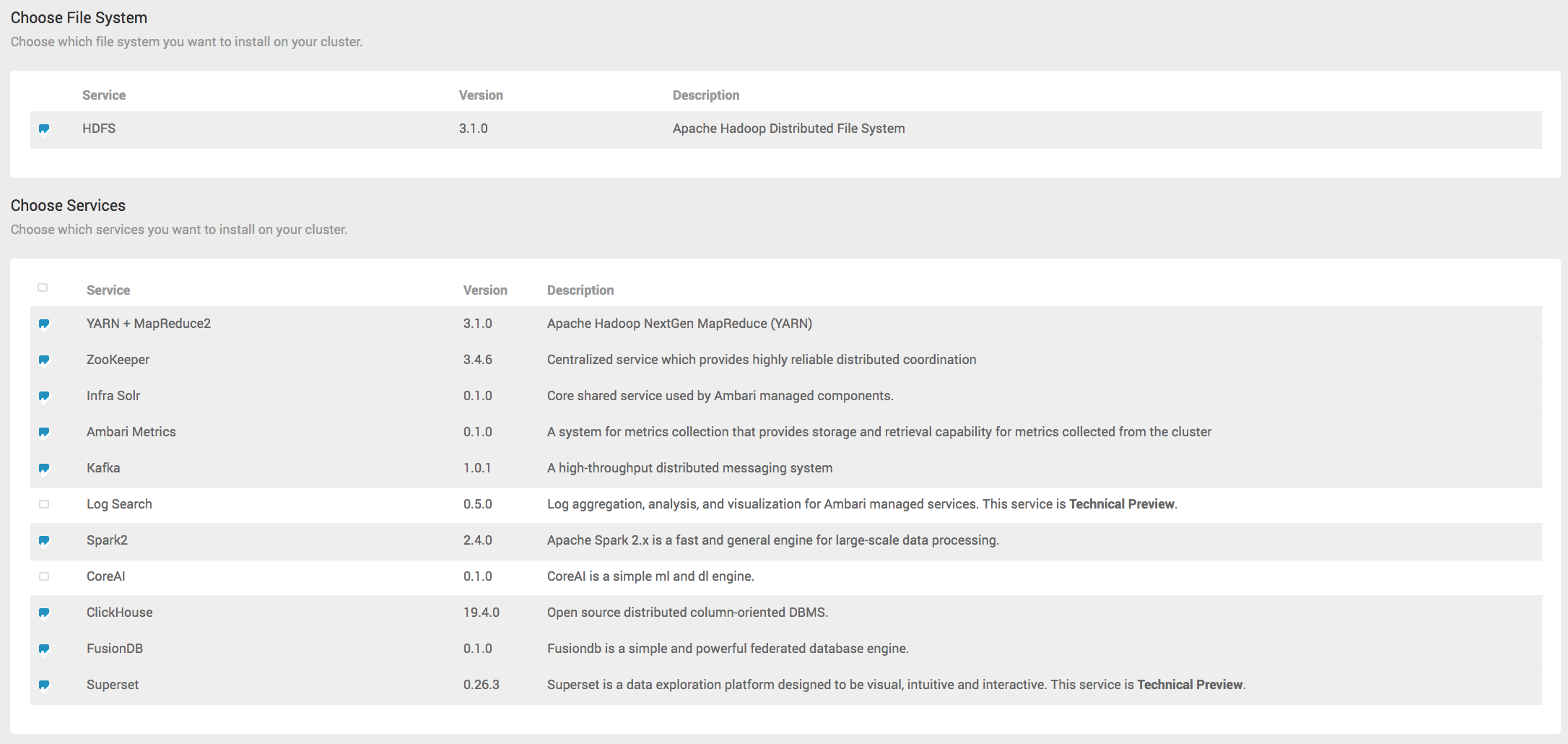
你需要勾选的服务如上所示,进行JDP集群的安装,点击Next。
# Step5 - Assign Masters
分配主节点所在主机,在分布式软件系统中,默认ClickHouse Server/Kafaka Borker只安装一个节点,通过点击+支持多节点。如下图:
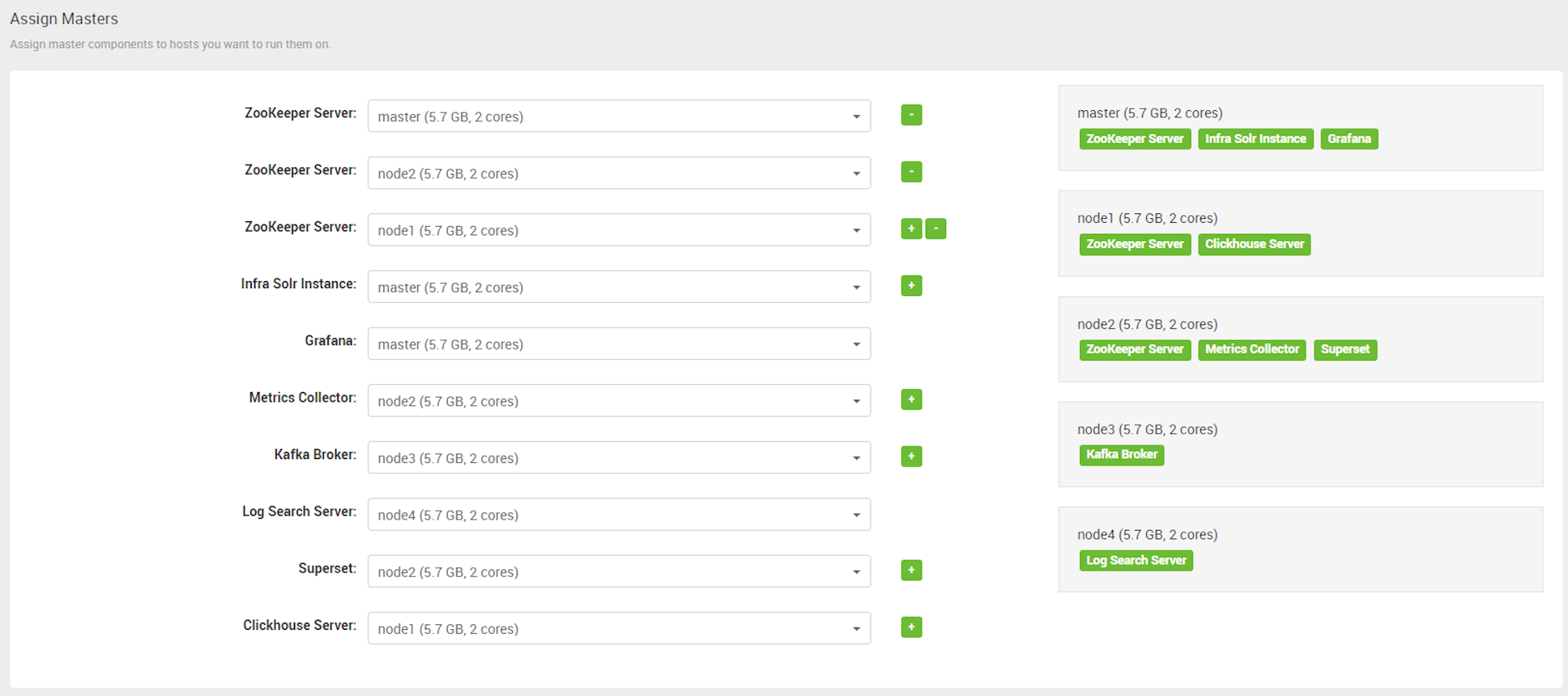
如下3个节点clickhouse server集群角色分配:
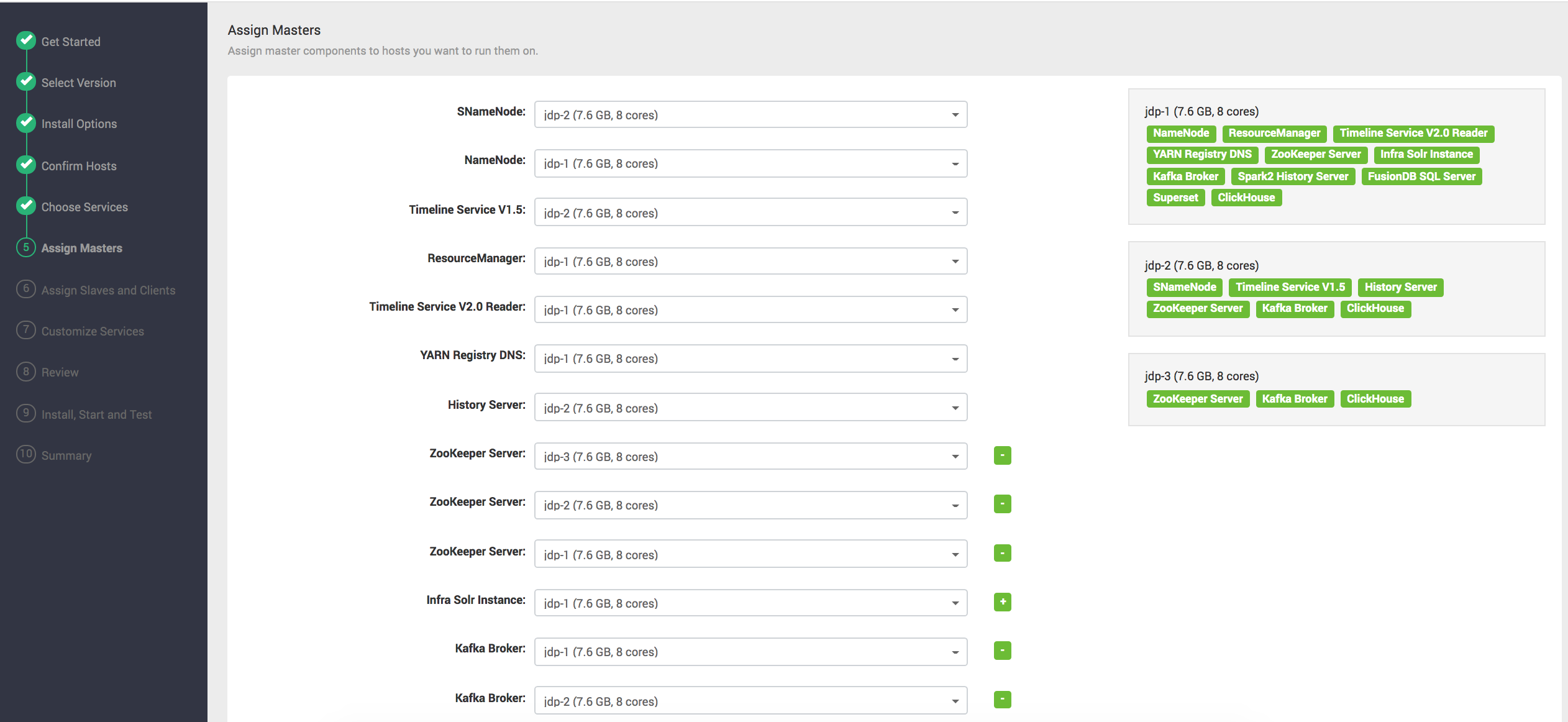
clickhouse,zookeeper与kafka broker对ambari来说是比较特殊的系统,因为他们是无中心设计,很多大数据系统都是Master-Slave设计,Ambari更擅长管理主从集群,通过他们安装向导你就能体会到,因为ambari最初是为Hadoop生态圈服务,我们对它进行改造服务于JDP流分析平台。
必须安装的相关服务选项,集群安装成功后,也可添加或删除服务,是非常灵活的。
关于上百个节点clickhouse server安装管理,可能会稍显麻烦,我们在以后版本中会进一步完善。
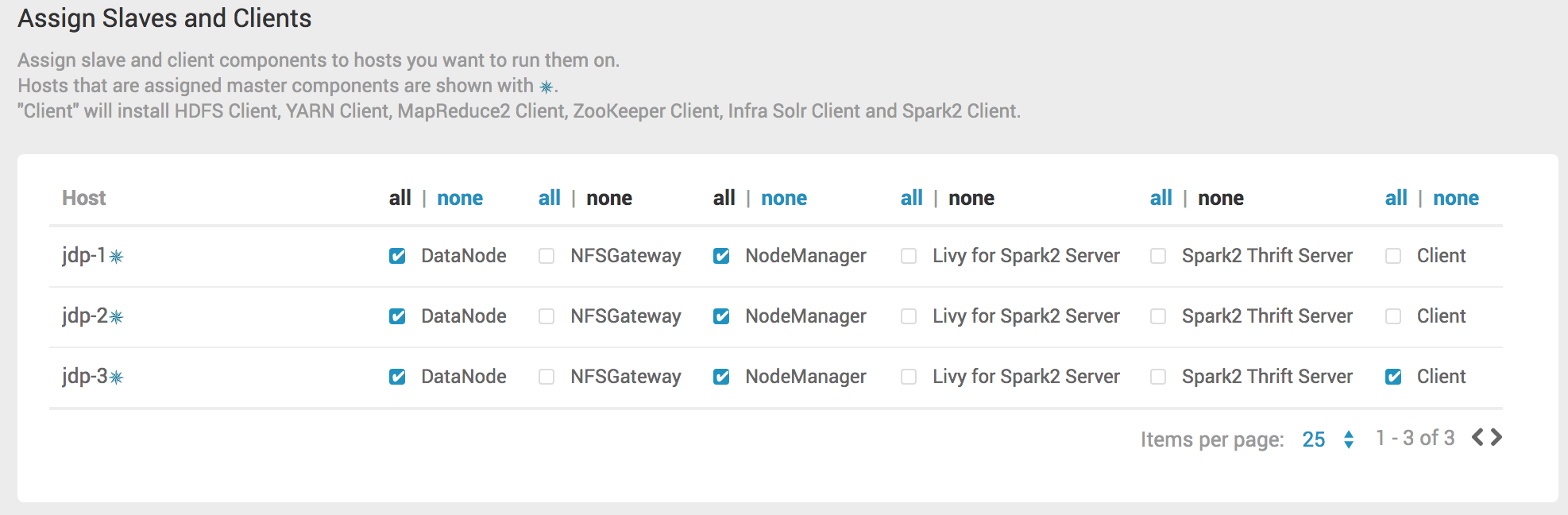
# Step6 - Assign Slaves and Clients
选择从节点和客户端所在主机,从节点和客户端是可以有多个的,可以进行自定义,默认会根据硬件做最小化选择从节点和客户端,这里可以根据需要选择从节点的分配。
- 从节点 – 有n个,一个节点就代表一台物理主机或者虚拟主机。
- 客户端 – 有n个,一般是客户机上需要安装客户端,让客户机可以访问集群服务。
# Step7 - Customize Services
自定义服务器配置,在这个步骤可以修改一些默认识别的参数,比如:ClickHouse存储的数据存储目录,Kafka/zookeeper存储数据的目录,最好在底层存储盘把他们隔离开来,因为它们的IO需求不同。
服务,需要自己根据提示输入一些用户密码的内容,请牢记相关服务器输入的用户密码,因为这些会在后台Ambari-server数据库中创建相应的数据库。指不定那天就需要登录后台数据库解决一些问题。
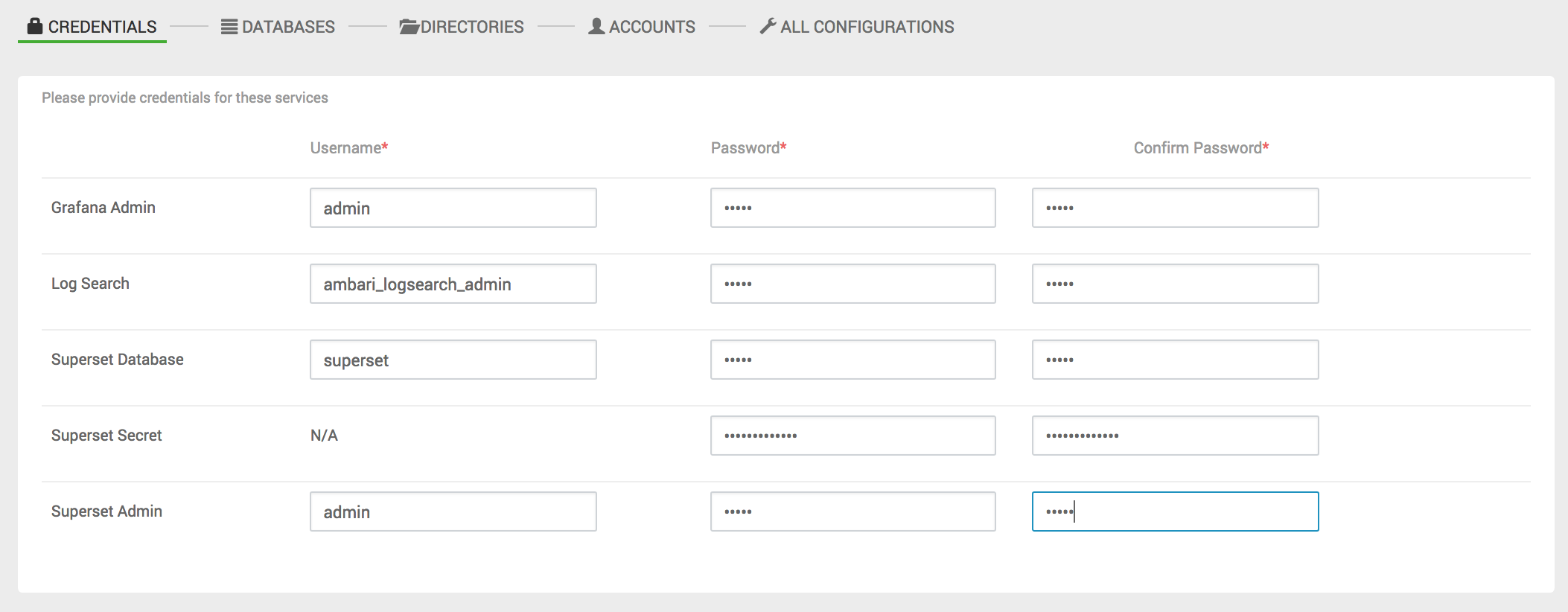
填写相关用户密码信息时,JDP流分析平台需要注意一下几点:
[1] Ambari Metrics
Grafana Admin Password密码,用于登录Grafana监控平台,监控集群相关服务的监控情况。
[2] ClickHouse
ClickHouse Server默认数据存储路径/data/clickhouse目录,如果此目录不存在自动创建, 不建议修改。
Advanced clickhouse-config 选项卡path中修改,tmp_path也请做相应修改。
目前已经支持90%左右的clickhouse server配置并且有相关配置信息提示,吐血梳理。
默认生成两个clickhouse user用户,用户登录clickhouse,进行相关操作。
- 管理员用户:admin/admin
- 只读ck用户:ck/admin
[3] Superset
Superset Secret Password, 请输入带有数字和字符的密码信息
Superset Admin Password,填写管理员密码
Superset Database Password,填写数据库密码
请牢记用户密码信息,在登录superset时需要使用到。
点击,Next进入下一步。
- DATABASES,Superset 数据库可持久化,默认使用:SQLITE,点击
Next下一步。 - DIRECTORIES,设置组件DATA DIRS,有默认值,点击
Next下一步。- ZOOKEEPER
- INFRA SOLR
- AMBARI METRICS
- KAFKA
- LOG SEARCH
- ACCOUNTS,点击
Next下一步。 - ALL CONFIGURATIONS,设置组件CONFIGURATIONS,点击
Next下一步。
注意:ClickHouse CONFIGURATIONS DATA DIR,默认路径:/data/clickhouse,可根据实际情况进行修改。
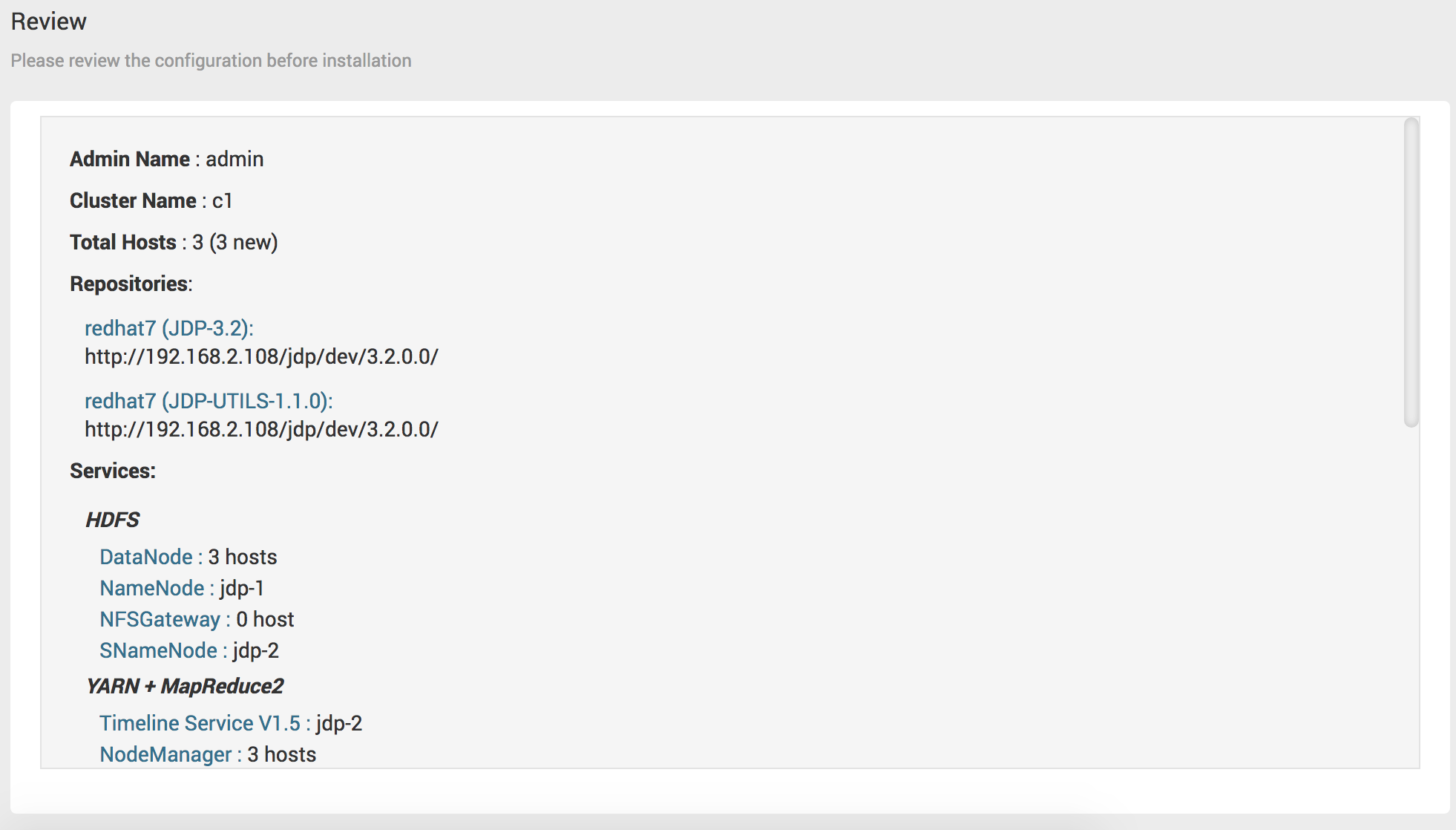
# Step8 - Review
在安装之前预览集群服务分配和节点相关信息是否正确,可以通过Print输出集群相关信息,如果检测没有任何问题,你就可以进行下一步Deploy了。
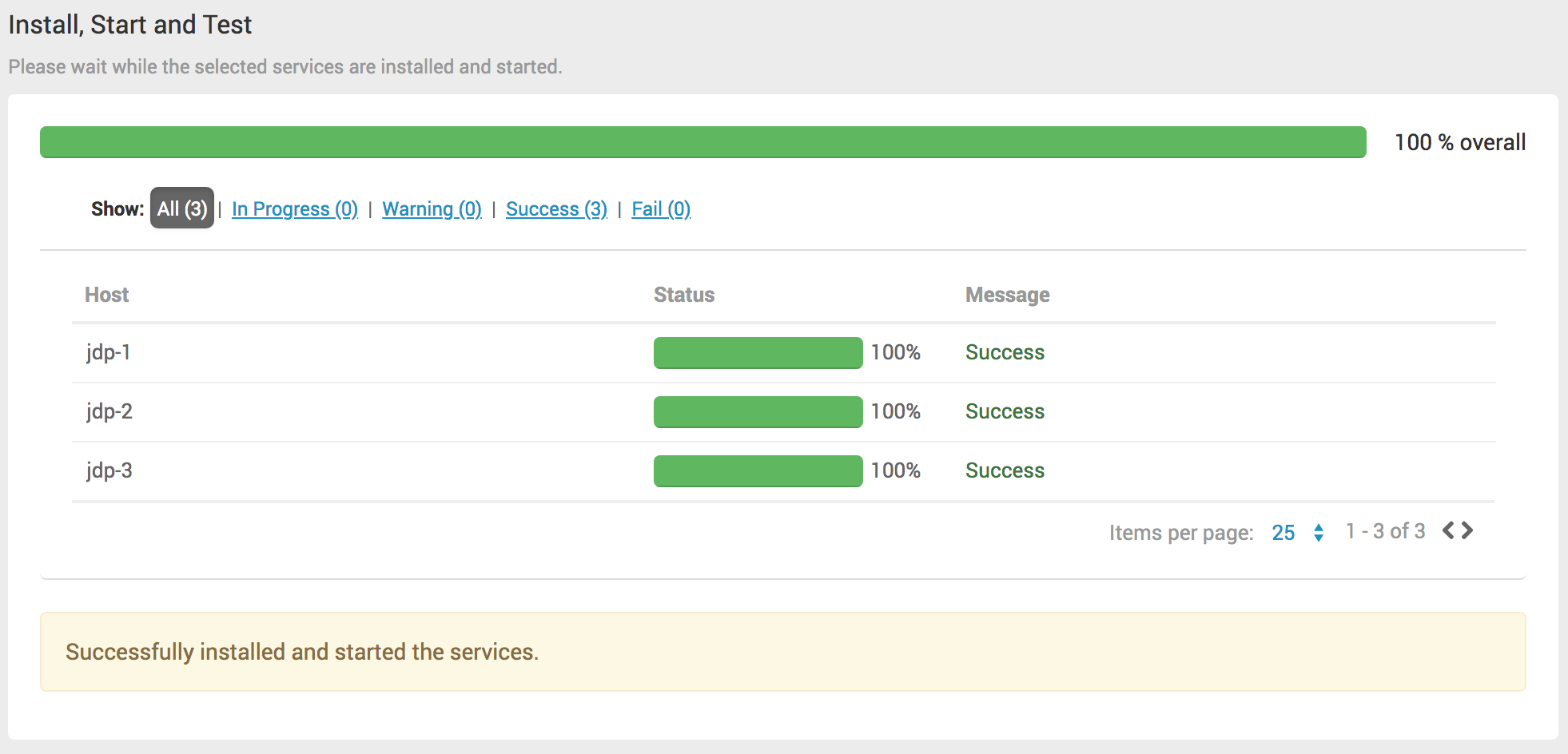
# Step9 - Install, Start and Test
自动化安装、启动集群、自动化Test集群,根据你的硬件环境和网络相关因素,你需要等待一段时间,等集群自动化安装成功,所有主机Status都变成绿色进度条,那就可以点击Next。
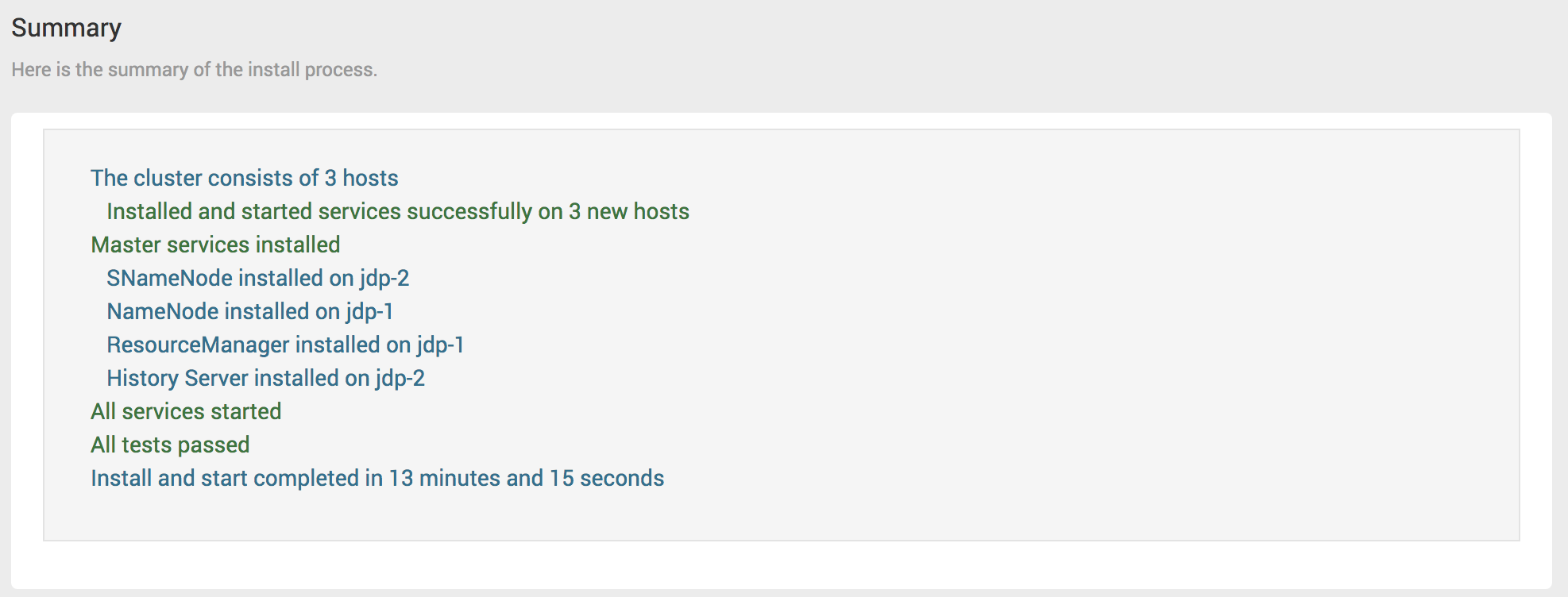
# Step10 – Summary
至此、集群安装完毕,开启你的JDP集群之旅吧。