快速启动
Fusiondb is a simple and powerful federated database engine.
# 快速安装
FusionDB 提供两种安装模式:
- Docker 快速安装体验单机版。
- JDP 一体化的产品,可视化的根据安装向导进行安装。
# 快速访问
FusionDB 是一个分布式的 OLAP 数据库,兼容 PostgreSQL 协议。用户可以使用标准的JDBC/ODBC 和 FusionDB 进行交互,示例如下:
- SQL Client 方式
- GUI 工具
# SQL Client 方式
使用 PostgreSQL 的 psql 与 FusionDB 直接交互或者使用第三方的 pgcli 类工具与 FusionDB 交互。
# Psql connects FusionDB
- 正常工作,fdb 为超级用户,不需要密码。
Psql 安装:
MacOS
brew install libpq # or brew install postgresql or brew remove postgresql@11.2
默认路径:/usr/local/opt/libpq/bin/psql
Ubuntu
sudo apt-get install postgresql-client
Redhat
sudo yum install https://download.postgresql.org/pub/repos/yum/10/redhat/rhel-7-x86_64/pgdg-redhat10-10-2.noarch.rpm
sudo yum install postgresql10
注意: 如果已安装postgresql数据库,则已经自带了psql,不需要单独安装client。
连接方式:
psql "sslmode=disable host=192.168.1.2 port=54322 dbname=default" --username=fdb
default=> show tables;
default | boxes | f
default | boxes_1 | f
default=> select * from my_table;
xiaoming | 29
xiaohua | 30
注意: 默认sslmode=disable,在未来的版本中会enabled.
# Pgcli connects FusionDB
- 不正常工作,主要是一些函数不支持,未来会适配。
连接方式:
pgcli 'postgres://fdb:123@172.27.137.232:54322/default?sslmode=disable'
Error:
== SQL ==
SHOW ALL
pgcli 参考:https://github.com/dbcli/pgcli
# GUI 工具
FusionDB 兼容 PostgreSQL 协议,支持 PostgreSQL 生态的一些可视化 GUI 工具执行 FQL,极大的方便用户快速上手 FusionDB。未来 FusionDB 会支持更多丰富的 SQL 语法。请使用我们测试验证过的第三方工具,否则不保证兼容性。
# FusionDB GUI PSequel
- host:FusionDB SQL Server 主机 IP
- user: fdb
- passowrd: 123456
- database: default
注意:使用 Mac 版本进行测试,连接 Use SSL 选项不勾选,默认即可,目前还未支持 Use SSL模式。
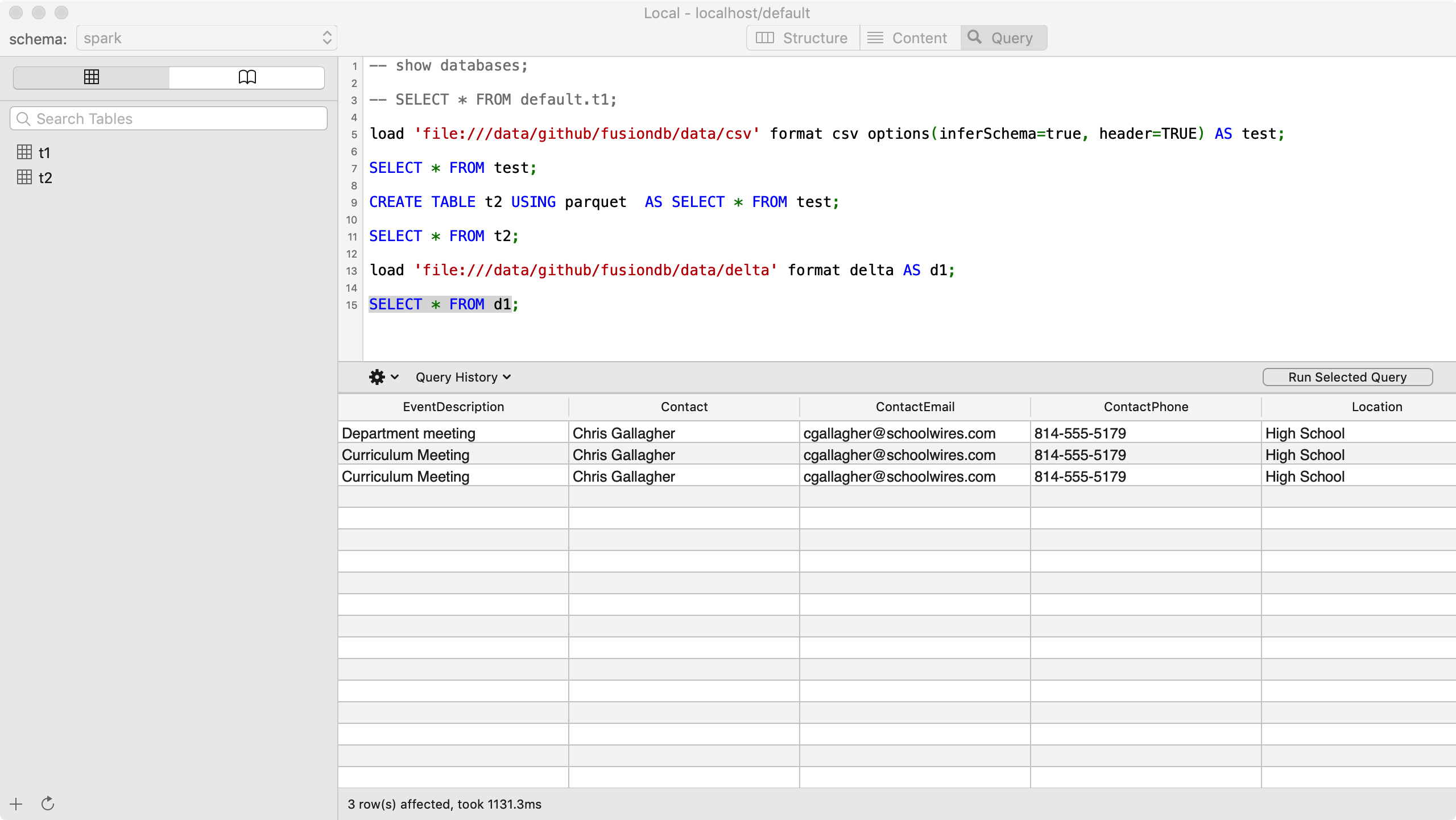
如下几个简单的示例,让我们来快速认识 FusionDB SQL 语法吧。
# FusionDB Join Psequel
- Load HDFS File
load 'hdfs://jdp-2:8020/tmp/spark-tpcds-data/store_sales' format parquet AS store_sales;
SELECT * FROM store_sales LIMIT 200;
show tables;
- Load RDBMS Table
- Load MySQL Table
load 'mysql' options('url'='jdbc:mysql://mysql-test1:3306/test','dbtable'='person','user'= 'root','password'='root') AS mysql_t2;
SELECT * FROM mysql_t2;
- Load PostgreSQL table
load 'postgresql' options('url'='jdbc:postgresql://pg-server-1:5430/test','dbtable'='person','user'= 'xujiang','password'='123') AS gp_t1;
SELECT * FROM gp_t1;
- MySQL Table Join PostgreSQL Table
SELECT * FROM mysql_t2 LEFT JOIN gp_t1 ON mysql_t2.id = gp_t1.id;
SELECT * FROM mysql_t2;
- Load datasource in query
Case1: query all data
load 'mysql' options('url'='jdbc:mysql://your_hostname:53306/test','dbtable'='t1','user'='root','password'='root') AS mysql_t2;
SELECT * FROM mysql_t2;
Case2: query supports pushdown
load 'mysql' options('url'='jdbc:mysql://your_hostname:53306/test','query'='select * from test.t1 where id=2','user'='root','password'='root') AS mysql_t2;
SELECT * FROM mysql_t2;
关于 Oracle,Greenplum,DB2,SQLServer,Teradata,Data Lake 使用示例。请参阅Data Sources
- Save table to HDFS
save APPEND gauss_t1 TO 'hdfs://jdp-2:8020/tmp/pg_test' format parquet;
save overwrite mysql_t2 TO 'hdfs://jdp-2:8020/tmp/pg_test' FORMAT PARQUET;
load 'hdfs://jdp-2:8020/tmp/pg_test' format parquet AS pg_test;
SELECT * FROM pg_test;
- Create Table in HDFS parquet
CREATE [TEMPORARY] TABLE [IF NOT EXISTS] [db_name.]table_name
[(col_name1 col_type1 [COMMENT col_comment1], ...)]
USING datasource
[OPTIONS (key1=val1, key2=val2, ...)]
[PARTITIONED BY (col_name1, col_name2, ...)]
[CLUSTERED BY (col_name3, col_name4, ...) INTO num_buckets BUCKETS]
[LOCATION path]
[COMMENT table_comment]
[TBLPROPERTIES (key1=val1, key2=val2, ...)]
[AS select_statement]
Examples
## create table in parquet/orc/csv/textfile/etc.
CREATE TABLE t3 USING parquet Options(path 'hdfs://plat-xujiang-cdsw:8020/tmp/web_site_test');
CREATE TABLE web_site_test USING PARQUET LOCATION 'hdfs://plat-xujiang-cdsw:8020/tmp/web_site_test';
## Create table
Case1:
CREATE TABLE t11 (`id` BIGINT, `name` STRING, `age` INT, `birthday` DATE);
INSERT INTO TABLE t11 values(1, '百度', 10, now()),(2, '阿里', 12, now());
SELECT * FROM t11;
CREATE TABLE boxes (width INT, length INT, height INT) USING CSV;
INSERT INTO TABLE boxes values(1, 33, 222),(2, 99, 888);
SELECT * FROM boxes;
Case 2:
CREATE TABLE boxes_1(width INT, length INT, height INT)
USING PARQUET
OPTIONS ('compression'='snappy');
INSERT INTO TABLE boxes_1 values(1, 33, 222),(2, 99, 888);
SELECT * FROM boxes_1;
CREATE TABLE boxes_5(width INT, length INT, height INT)
USING ORC
OPTIONS ('compression'='snappy');
INSERT INTO TABLE boxes_5 values(1, 33, 222),(2, 99, 888);
SELECT * FROM boxes_5;
CREATE TABLE boxes_6(width INT, length INT, height INT)
USING CSV
OPTIONS ('compression'='snappy');
INSERT INTO TABLE boxes_6 values(1, 33, 222),(2, 99, 888);
SELECT * FROM boxes_6;
## Create temporary table
CREATE TEMPORARY TABLE boxes
(width INT, length INT, height INT)
USING PARQUET
OPTIONS ('compression'='snappy')
## Create parquet table with select result
CREATE TABLE rectangles
USING PARQUET
PARTITIONED BY (width)
CLUSTERED BY (length) INTO 8 buckets
AS SELECT * FROM boxes
- Create Table with Hive format
CREATE [EXTERNAL] TABLE [IF NOT EXISTS] [db_name.]table_name
[(col_name1[:] col_type1 [COMMENT col_comment1], ...)]
[COMMENT table_comment]
[PARTITIONED BY (col_name2[:] col_type2 [COMMENT col_comment2], ...)]
[ROW FORMAT row_format]
[STORED AS file_format]
[LOCATION path]
[TBLPROPERTIES (key1=val1, key2=val2, ...)]
[AS select_statement]
row_format:
: SERDE serde_cls [WITH SERDEPROPERTIES (key1=val1, key2=val2, ...)]
| DELIMITED [FIELDS TERMINATED BY char [ESCAPED BY char]]
[COLLECTION ITEMS TERMINATED BY char]
[MAP KEYS TERMINATED BY char]
[LINES TERMINATED BY char]
[NULL DEFINED AS char]
file_format:
: TEXTFILE | SEQUENCEFILE | RCFILE | ORC | PARQUET | AVRO
| INPUTFORMAT input_fmt OUTPUTFORMAT output_fmt
Examples
DROP TABLE my_table;
CREATE TABLE my_table (name STRING, age INT);
INSERT INTO TABLE my_table values('xiaoming', 29),('xiaohua', 30);
SELECT * FROM my_table;
CREATE TABLE my_table_1 (name STRING, age INT)
COMMENT 'This table is partitioned'
PARTITIONED BY (hair_color STRING COMMENT 'This is a column comment')
TBLPROPERTIES ('status'='staging', 'owner'='andrew');
CREATE TABLE my_table_2 (name STRING, age INT)
COMMENT 'This table specifies a custom SerDe'
ROW FORMAT SERDE 'org.apache.hadoop.hive.ql.io.orc.OrcSerde'
STORED AS
INPUTFORMAT 'org.apache.hadoop.hive.ql.io.orc.OrcInputFormat'
OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.orc.OrcOutputFormat';
CREATE TABLE my_table_3 (name STRING, age INT)
COMMENT 'This table uses the CSV format'
ROW FORMAT DELIMITED FIELDS TERMINATED BY ','
STORED AS TEXTFILE;
CREATE TABLE your_table
COMMENT 'This table is created with existing data'
AS SELECT * FROM my_table;
CREATE EXTERNAL TABLE IF NOT EXISTS my_table_4 (name STRING, age INT)
COMMENT 'This table is created with existing data'
LOCATION 'spark-warehouse/tables/my_existing_table';
SELECT * FROM my_table_4;
## Create Table Like
CREATE TABLE IF NOT EXISTS default.tt1 LIKE default.t3 LOCATION 'hdfs://plat-xujiang-cdsw:8020/tmp/web_site_test';
SELECT * FROM tt1;
注意:选中想要执行的语句,点击运行按钮进行 FQL 的执行。此工具选中多条 FQL 执行时,逗号分隔,不支持执行,由于是第三方工具,目前暂未修复此问题。
# FusionDB Join Pandas
- Psycopg2 connecting FDB
import psycopg2
import pandas as pd
connection = psycopg2.connect(“host=localhost port=5432 dbname=default user=xujiang sslmode=disable”)
df = pd.read_sql(sql=”SELECT * FROM VALUES (1, 1), (1, 2) AS t(a, b);”, con=connection)
df
a b
0 1 1
1 1 2
df = pd.read_sql(sql=”show databases;”, con=connection)
df = pd.read_sql(sql=”show tables;”, con=connection)
注: psycopg2 连接时,需要 sslmode=disable,因为还未支持,未来版本会支持。
- Local csv file to parquet
df = pd.read_sql(sql=”load ‘file:///data/github/fusiondb/data/csv/‘ format csv options(‘inferSchema’=’true’, ‘header’=’true’) as t1”, con=connection)
df =pd.read_sql(sql=”desc t1”, con=connection)
df = pd.read_sql(sql=”save APPEND T1 TO ‘file:///data/github/fusiondb/data/csv/t1‘ format parquet”, con=connection)
- Load csv file to HDFS parquet
df = pd.read_sql(sql=”load ‘file:////data/github/fusiondb/data/userdata2.parquet’ format parquet as c2;”, con=connection)
df = pd.read_sql(sql=”save APPEND T1 TO ‘hdfs://jdp-1:8020/tmp/t1‘ FORMAT PARQUET;”, con=connection)
df =pd.read_sql(sql=”load ‘hdfs://jdp-1:8020/tmp/t1‘ format parquet as t2;”, con=connection)
df =pd.read_sql(sql=”show tables;”, con=connection)
df =pd.read_sql(sql=”desc t2;”, con=connection)
- Load parquet file to MySQL t3
df = pd.read_sql(sql=”load ‘file:////data/github/fusiondb/data/userdata2.parquet’ format parquet as c2;”, con=connection)
df = pd.read_sql(sql=”save overwrite c2 TO ‘hdfs://jdp-1:8020/tmp/t1‘ FORMAT PARQUET;”, con=connection)
df = pd.read_sql(sql=”load ‘hdfs://jdp-1:8020/tmp/t1‘ format parquet as h1”, con=connection)
df = pd.read_sql(sql=”select * from h1”, con=connection)
df.head()
df = pd.read_sql(sql=”select current_database();”, con=connection)
df = pd.read_sql(sql=”save h1 to ‘mysql’ options(‘url’=”jdbc:mysql://mysql-server:3306/test”,’dbtable’=’h1,’user’= ‘test’,’password’=’123’);”, con=connection)
# FAQ
-
关于 MYSQL,PostgreSQL 驱动:需要自己下载安装到 JDP 的 FusionDB lib 目录下,才可以正常使用。
-
关于支持从 Local 加载数据:这里指的 Local 是 FusionDB SQL Server 安装节点 Linux 本机本地的数据。开发调试时Local模式安装,能做到 Local 到集群的读写操作,生产环境目前不建议如此。
-
关于 FusionDB SQL 语法支持:支持 SQL 99 标准,其他 SQL++ 部分是自己扩展的 SQL 语法,未来功能请关注 roadmap 。
-
关于跨多云协作、查询、分析:在下一个版本 release,目前未测试稳定。
-
关于
Data Lake支持事物,实时、批量写数据: 在下一个版本 release,目前未测试稳定。 -
关于
Data Lake支持批流语法统一,批流数据一致问题: 在下一个版本 release,目前未测试稳定。 -
关于,FQL 除标准 SQL 外,一些 SQL++ 语法为何这样丑,完全不像是做数据库的人弄出来的语法:早期设计问题,对事物规律的统一归纳考虑不全。Next 批流语法统一时,会遵循标准数据库语法,扩展新的语法时,尽量不造新概念。作者也是在努力学习如何做一个数据库呢,请圈内的大佬们多包涵。